A complete map of all major AI crawlers powering ChatGPT, Gemini, Claude, Perplexity, Copilot, Apple Intelligence, and more.
Who crawls your site, why, and how it affects your AI search visibility.
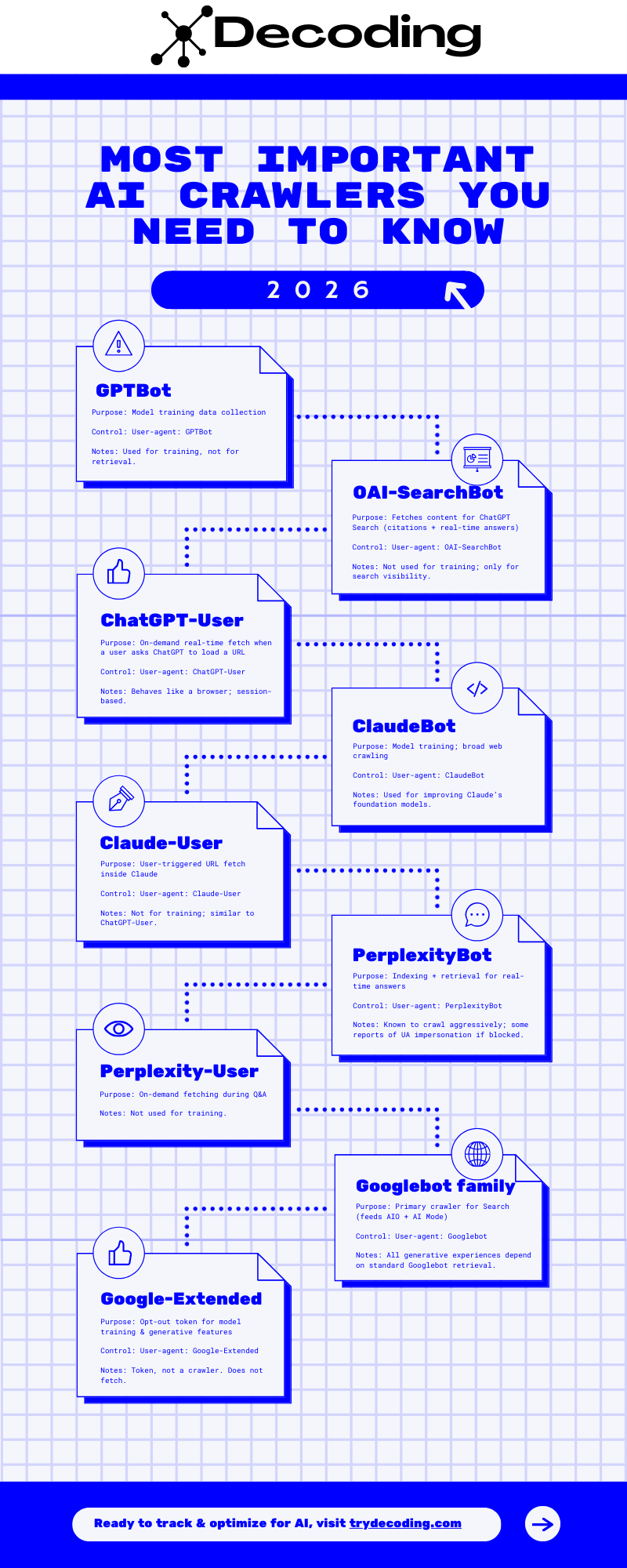
1. OpenAI (ChatGPT / GPT-4.1 / GPT-5)
GPTBot
- Purpose: Model training data collection
- Control:
User-agent: GPTBot - Notes: Used for training, not for retrieval.
OAI-SearchBot
- Purpose: Fetches content for ChatGPT Search (citations + real-time answers)
- Control:
User-agent: OAI-SearchBot - Notes: Not used for training; only for search visibility.
ChatGPT-User
- Purpose: On-demand real-time fetch when a user asks ChatGPT to load a URL
- Control:
User-agent: ChatGPT-User - Notes: Behaves like a browser; session-based.
2. Anthropic (Claude)
ClaudeBot
- Purpose: Model training; broad web crawling
- Control:
User-agent: ClaudeBot - Notes: Used for improving Claude’s foundation models.
Claude-User
- Purpose: User-triggered URL fetch inside Claude
- Control:
User-agent: Claude-User - Notes: Not for training; similar to ChatGPT-User.
3. Perplexity
PerplexityBot
- Purpose: Indexing + retrieval for real-time answers
- Control:
User-agent: PerplexityBot - Notes: Known to crawl aggressively; some reports of UA impersonation if blocked.
Perplexity-User
- Purpose: On-demand fetching during Q&A
- Notes: Not used for training.
4. Google (Gemini, AI Overviews, AI Mode)
Googlebot family
- Purpose: Primary crawler for Search (feeds AIO + AI Mode)
- Control:
User-agent: Googlebot - Notes: All generative experiences depend on standard Googlebot retrieval.
Google-Extended
- Purpose: Opt-out token for model training & generative features
- Control:
User-agent: Google-Extended - Notes: Token, not a crawler. Does not fetch.
5. Apple (Apple Intelligence)
Applebot
- Purpose: Indexing for Siri, Spotlight, Apple services
- Control:
User-agent: Applebot
Applebot-Extended
- Purpose: Opt-out for Apple’s model training
- Control:
User-agent: Applebot-Extended - Notes: Token equivalent to Google-Extended.
6. Microsoft (Bing / Copilot / Edge Assistant)
bingbot
- Purpose: Core Bing index (feeds Copilot AI answers)
- Control:
User-agent: bingbot
7. You.com
YouBot
- Purpose: Crawling for You.com’s AI search
- Control:
User-agent: YouBot
8. Cohere
cohere-training-data-crawler
- Purpose: Training crawler
- Control:
User-agent: cohere-training-data-crawler
cohere-ai
- Purpose: On-demand fetcher used by Cohere chat products
- Notes: Observed in the wild; mixed behavior.
9. Common Crawl
CCBot
- Purpose: Open-source crawl used in many AI model training datasets
- Control:
User-agent: CCBot - Notes: Major upstream data source for AI companies.
10. Allen Institute (AI2 / Semantic Scholar)
AI2Bot
- Purpose: Research crawling; feeds Semantic Scholar
- Control:
User-agent: AI2Bot
11. Meta
FacebookBot / facebookexternalhit / meta-externalagent
- Purpose: Social previews; possible use in Meta AI
- Notes: Not directly confirmed as AI retrieval bots.
12. ByteDance (TikTok / Toutiao / CapCut)
Bytespider
- Purpose: Wide crawl; supports TikTok/AI content features
- Control:
User-agent: Bytespider
13. Amazon
Amazonbot
- Purpose: Crawling for Amazon properties, potentially AI use
- Control:
User-agent: Amazonbot
14. DuckDuckGo
DuckAssistBot
- Purpose: Fetching for DuckAssist answer engine
- Control:
User-agent: DuckAssistBot
15. Diffbot
Diffbot
- Purpose: ML extraction service; often upstream for AI datasets
- Control:
User-agent: Diffbot
16. Omgili / Omgili Bot
omgili
- Purpose: Scrapes forums + discussions (used in AI pipelines)
- Control:
User-agent: omgili
17. Timpi (Decentralized Search)
Timpibot / TimpiBot
- Purpose: Distributed search indexer
- Notes: Increasingly seen in AI startup stacks.









Leave a Reply